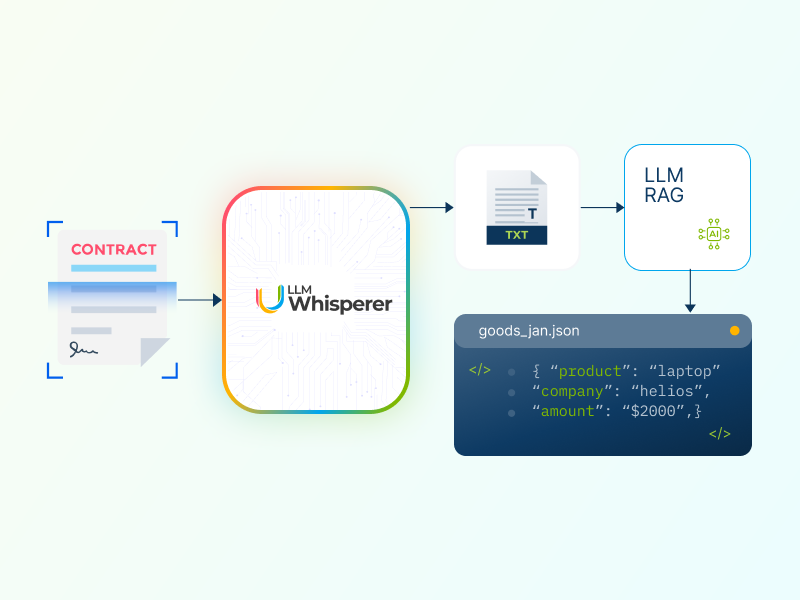
Prep data from complex documents for use in Large Language Models
LLMs are powerful, but their output is as good as the input you provide.
Documents can be a mess: widely varying formats and encodings, scans of images, numbered sections, and complex tables. Extracting data from these documents and blindly feeding them to LLMs is not a good recipe for reliable results.
LLMWhisperer is technology that presents data from complex documents to LLMs in a way they’re able to best understand it.
Playground Sign up Explore APIs