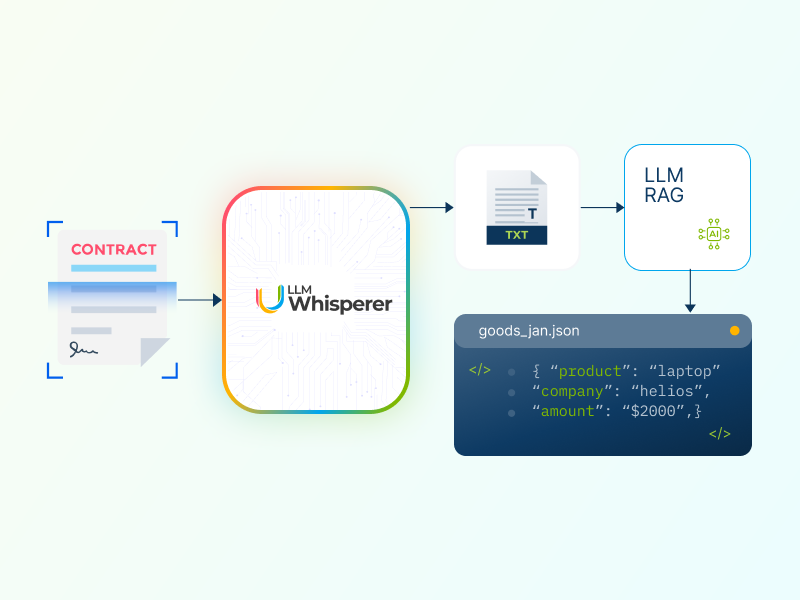
Prep data from complex documents for use in Large Language Models
LLMs are powerful, but their output is as good as the input you provide.
Documents can be a mess: widely varying formats and encodings, scans of images, numbered sections, and complex tables. Extracting data from these documents and blindly feeding them to LLMs is not a good recipe for reliable results.
LLMWhisperer is technology that presents data from complex documents to LLMs in a way they’re able to best understand it.
Alert!
You're accessing LLMWhisperer v1, which is deprecated. While you can continue to use LLMWhisperer v1,
you should know that LLMWhisperer v2 has better performance and more features.
What's more? LLMWhisperer v2 sports a simple, no-upfront, pay-as-you-go billing model.
LLMWhisperer v2 is a separate product and requires its own subscription.
If you are a paying v1 customer, please cancel your subscription and subscribe to v2.
Switching to v2 is super simple with our Python client.